Google Search is an entirely automated search engine that makes use of pieces of software referred to as web crawlers. These web crawlers explore the web on a regular basis in order to locate new pages that can be added to Search engine index.
In point of fact, the vast majority of pages that are indexed in results are not those that have been submitted by hand for consideration for inclusion. Rather, these pages are discovered and added automatically by web crawlers as they navigate the web.
Within the context of your website, the stages of the Search functionality are explained here. If you have this foundational knowledge, you will be better equipped to resolve crawling issues, get your pages indexed, and learn how to optimise the way your site appears in Google Search.
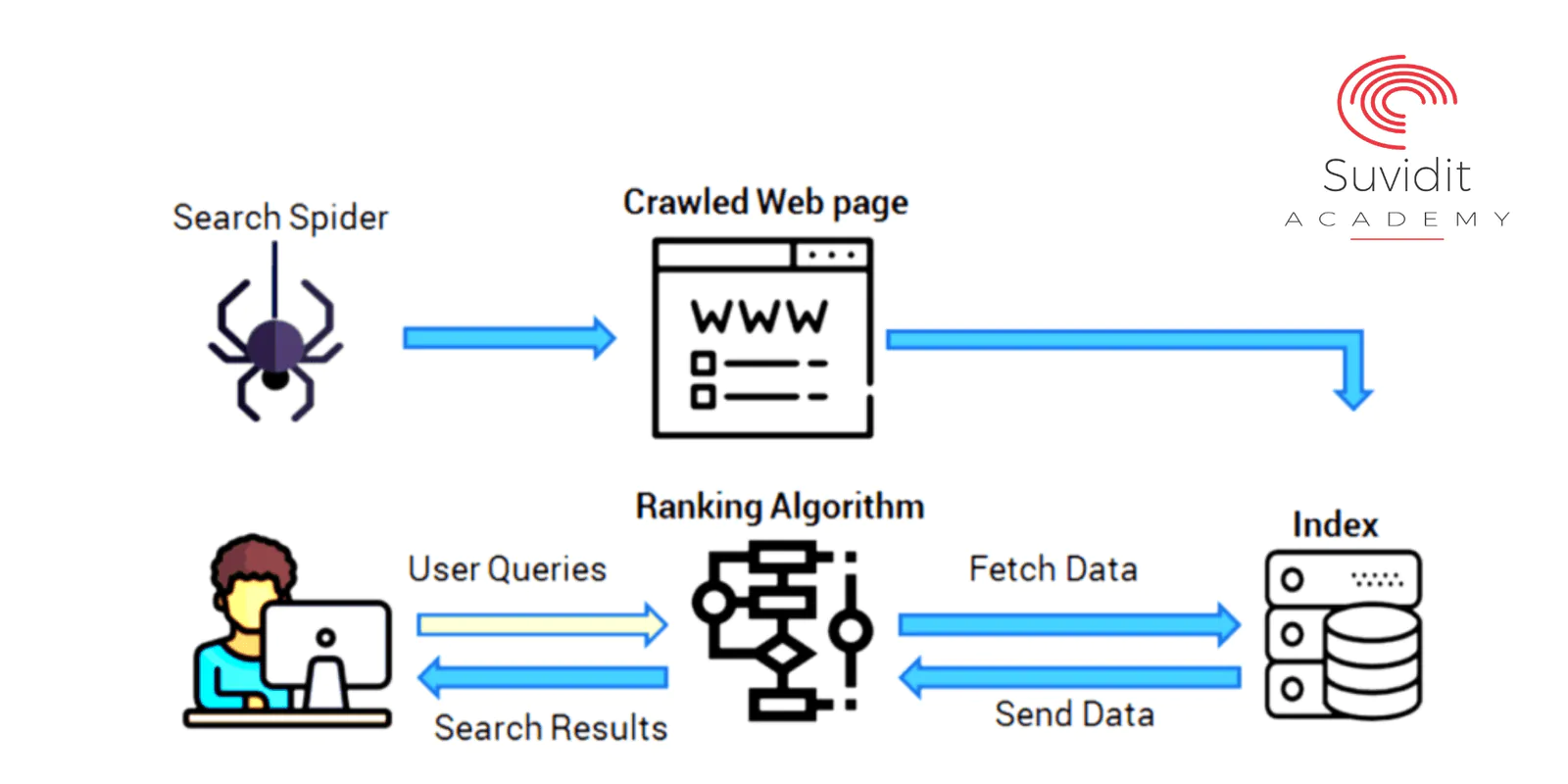
The first, the second, and the third stages of your Google search
There are three stages to the process that Google Search goes through, and not all pages are able to pass through each stage:
- Crawling :- Crawling is the process by which Google gathers information such as text, images, and videos from websites it discovers on the internet using automated programmes known as crawlers.
- Indexing :- Google performs an analysis of the text, images, and video files on the page, and then stores the information in the Google index, which is a large database. This process is known as indexing.
- Serving search results :- When a user conducts a search on Google, Google will return information that is pertinent to the user’s query in order to serve search results.
Crawling
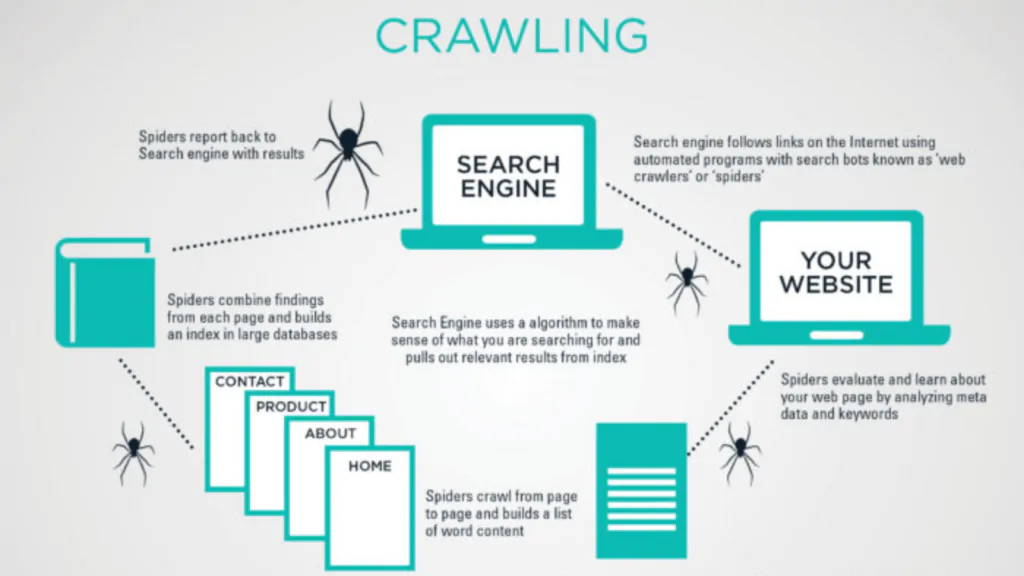
The initial step is to investigate what kinds of pages can be found on the internet. Because there is no centralised registry of all web pages, Google has to consistently look for new and updated pages and add them to its list of known pages. This keeps Google’s index current. The method in question is known as “URL discovery.” Some pages are already familiar to Google because the search engine has been there before. Other pages are found when Google follows a link from a known page to a new page; for instance, when a hub page, such as a category page, links to a new blog post. Other pages are found when Google follows a link from a known page to a new page. When you submit a list of pages, known as a sitemap, for Google to crawl, it also leads to the discovery of additional pages.
After Google has located the URL of a page, it may proceed to visit (also known as “crawl”) the page in order to learn more about its contents. Search Engine crawl through the billions of pages on the web using a massive network of computers. The name of the programme that actually does the retrieving is Googlebot (also known as a robot, bot, or spider). The selection of which websites to crawl, how frequently to crawl them, and how many pages from each website to fetch is all determined by an algorithm used by Googlebot. The web crawlers used by Google are also programmed in such a way that they make an effort not to crawl the site too quickly in order to prevent it from becoming overloaded. This mechanism takes into account both the responses of the site (for instance, HTTP 500 errors mean “slow down”) as well as the settings in Search Console.
Despite this, Googlebot does not crawl each and every page that it has discovered. Some pages might not be accessible without first logging in to the site, some pages might be duplicates of pages that have already been crawled, and some pages might be disallowed from being crawled altogether by the site’s owner. For instance, the content of many websites can be accessed through either the “www” (www.example.com) or “non-www” (example.com) version of the domain name, despite the fact that both versions contain the same information.
During the crawl, Google uses an up-to-date version of Chrome to render the page and execute any JavaScript that it discovers. This process is very similar to how your browser renders pages that you visit. Rendering is essential because websites frequently rely on JavaScript to bring content to the page; if rendering is not performed, Google may be unable to see this content. Rendering can prevent this from happening.
The ability of Google’s crawlers to access the site is a prerequisite for crawling. The following is a list of issues that frequently arise when Googlebot attempts to access sites:
- There are issues with the server that manages the website.
- Problems with the network
- directives in the robots.txt file that prevent Googlebot from accessing the page
Indexing

After Google has finished crawling a page, the search engine will attempt to comprehend the page’s subject matter. Indexing is the stage that entails processing and analysing the textual content in addition to the key content tags and attributes. Examples of these include title> elements and alt attributes, images, videos, and a variety of other media types.
While a page is being indexed, Google checks to see if it is a duplicate of another page on the internet or if it is the canonical version of the page. The canonical page is the one that has the potential to be displayed in search engine results. In order to choose the page that will serve as the canonical source, Search Engine first organise the web pages that was discovered to have content that is comparable, and then search engine choose the page that is the best example of the collective. The other pages in the group are alternate versions that may be served in different contexts, such as when the user is searching from a mobile device or when they’re looking for a very specific page from that cluster. For example, if the user is searching from a mobile device, the user may be served an alternate page.
Additionally, Google collects signals regarding the canonical page and its contents. These signals have the potential to be used in the subsequent stage, which is when the page is served up in search results. The language of the page, the country that the content is local to, the usability of the page, and other factors are all considered to be signals.
The information that has been gathered concerning the canonical page and its cluster might be saved in the Google index, which is a massive database that is hosted on thousands of computers. There is no assurance that every page that Google processes will be indexed; indexing is not a given.
Indexing is also dependent on the information that is contained on the page’s metadata. The following are some examples of common indexing problems:
- There is a significant lack of high-quality content on the page.
- Indexing is forbidden by the robots’ meta directives.
- It’s possible that the layout of the website will make indexing more difficult.
Serving search results
When a user enters a query into search engine, machines search the index for matching pages and return the results that believe to be of the highest quality and most relevant to the user. The level of relevance is based on a multitude of factors, some of which are the location of the user, the language they speak, and the type of device they are using (desktop or phone). For instance, if a user were in Paris and they searched for “bicycle repair shops,” they would get different results than if they were in Hong Kong and they did the same search.
Even though Search Console has informed you that a page has been indexed, you may not be able to find it in the search results. It’s possible that this is due to:
- Users don’t care about the content of the page, so it shouldn’t be there.
- The standard of the material is very poor.
- The meta directives of robots prevent them from serving.
While this guide does an adequate job of explaining how Search works, please note that Search Engines are continually working to improve the algorithms.





